NTTコミュニケーション科学基礎研究所の中谷智広さん、荒木章子さんらの研究グループでは、さまざまな音が混じり合った音声から、雑音などの不要な音を取り除きながらそれぞれの音を取り出す音源分離の技術や、音声認識の邪魔になる残響を取り除く技術の開発などを手がけている。最近では、深層ニューラルネットワーク技術を使った画期的な手法により、世界コンペティションで1位を獲得した。スマートフォンやスマートスピーカーの音声認識の向上に資する研究について話を聞いた。
コンピュータはすべての音を分けて、取り出して聞く
柏野 私が学生の頃というと、もう30年も前になりますが、当時、音声認識を語る際、前置きとして「人間の能力に比べて、コンピュータはまだまだ劣る」という言葉が枕詞のように使われていました。実際に当時は、音声認識のためにあらかじめ登録した話し手が明瞭に発話した音声は認識できても、それ以外の話者の音声や、通常の日常会話の認識はお手上げでした。その後、コンピュータが飛躍的に進化を遂げたことで、いまや一部の能力については完全に人間を凌駕するようになりました。スマートスピーカーの普及も急速に進んでいますね。
そうした状況のなか、中谷さん、荒木さんらのグループはNTTコミュニケーション科学基礎研究所(CS研)において、長年にわたり世界トップレベルの音声認識技術の研究を続け、数年前には、音声認識のコンペティションで世界1位を獲得しました。本日はぜひ、その研究内容について聞かせてください。
中谷 確かに、すでにコンピュータは発話を聞き取ることに関しては、ある意味、人間を超えています。ご存知にように、いまや音声認識技術を使ってスマートフォンで調べ物をしたり、スマートスピーカーで商品を注文したりということが普通にできるようになりました。
一方で、人間が当たり前にできることが、いまだに全然できないという側面もあります。
たとえば、複数人がテーブルを囲んで会話をしているとしましょう。そのテーブルの真ん中にICレコーダーを置いて録音します。後ろのテーブルでは、別のグループも話をしています。皆、自由なタイミングで話しますし、ときには別の人が会話に割って入ることもあります。当然、ICレコーダーには、記録したい会話のほか、別グループの人の声や、壁や天井に反射した残響、空調の音など、さまざまな雑音も録音されます。録音を再生して聞くと、マイクから遠い人の声ほど聞き取りづらいということがよくあるでしょう。
このように、複数人で会話をしているような状況や、街中の騒がしい環境で音声をきちんと認識できるインタフェイスというのは、まだありません。それを実現したい、というのが我々の研究グループのモチベーションになっています。つまり、私たちの生活の中に自然に溶け込んで音声認識をサポートする技術を確立したいと考えています。
—音声認識技術はここ数年で大きく進化してきたけれど、一方で、まだまだ日常的な環境のなかで使うことは難しいのですね。
荒木 ええ。では、さまざまに混じり合う音がある中で、コンピュータが人の声だけをうまく拾うにはどうすればいいのか。この問題を解くために、基本的には音源ごとにバラバラに分離するという方法が用いられています。
我々が十数年前に開発した「ブラインド音源分離技術」というのも、まさに音を分けて聞くという方法の一つです。これは、それぞれの音を特徴づけるスペクトル構造などの情報を使わずに、つまり音源がどういうものであるかを知らないで(=ブラインド)、混じり合った音を分解する手法です。
まず、複数のマイクロフォンで観測した音を周波数帯域に分解します。次に、周波数帯域ごとに、たとえば独立成分分析などの手法で、互いに無関係な成分を分離します。それらの成分はそれぞれ別の音源から発せられたものと考えられます。
分離した信号を復元するには、その音源に対応するすべての周波数成分を足し合わせる必要があります。しかし、独立成分分析では、音が出力される順序がそれぞれの周波数帯域でまちまちになるので、周波数帯域間でどれとどれが対応しているのかがわからなくなり、正しく信号を復元できない。従来、難しかったのはまさにこの点です。
そこで我々は、分離された周波数成分が音源の位置に相当する情報を持っていることに着目して、同じ音源の成分をクラスタリングする、すなわちひとまとめにする手法を開発しました。この方法により、正しく分離信号を復元できるだけでなく、それぞれの音の方向を推定することができるようになりました。これにより同時に2人の人が話していても、音源の方向から、どちらの発言かを当てることができるようになったのです。
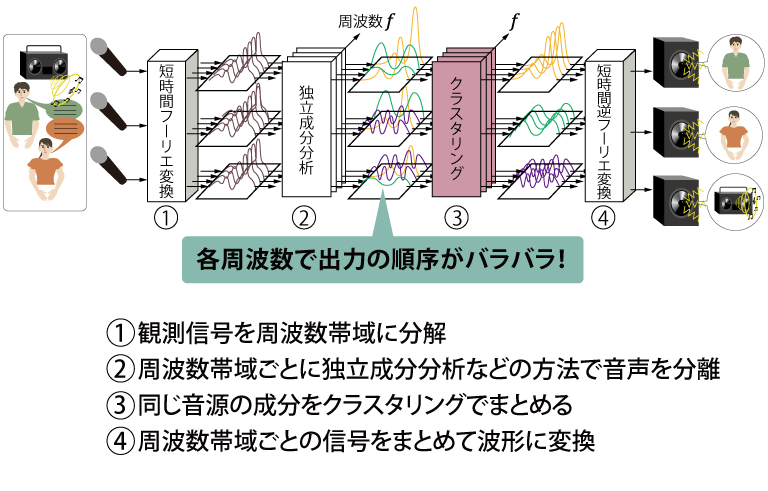
図1 ブラインド音源分離のしくみ
柏野 これは、人間には到底真似できないやり方ですね。人間の場合は、聞きたい音にだけに注意を向け、そのほかの音は意識することもなく無視する。一方、コンピュータはすべての音を取り込んで、バラバラにして聞く。これこそが、ある意味、コンピュータのすごいところであり、逆にダメなところでもあります。
ところで、残響がある場合には、独立成分分析だけではうまく分離できませんよね?
中谷 はい、そこで我々は10年ほど前に、音声認識で培ったパターン処理(雑多な情報の中から、一定の規則や意味を選別して取り出す手法)の考え方を音響処理に取り込むことで、録音された音声から残響を取り除く技術を世界で初めて開発しました。こうした技術を組み合わせて、改善を重ねることで、近年、音声認識技術を急激に発達させてきたというわけです。
音声認識の国際コンペティションで世界第1位を獲得
中谷 そうしたなか、我々は数年前に、雑音や残響のある公共エリアの雑音下でのモバイル音声認識の国際コンペティションで、大きな成果をあげました。
2015年に開催されたCHiME-3という大会で、最新の音声認識であるロバスト音声認識を使って、まず、単語の誤り率を15%程度にまで下げることに成功しました。これは、畳み込みニューラルネットワーク(CNN:Convolutional Neural Network)という、深層ニューラルネットワーク(Deep Neural Network:DNN)の技術を使ったものです。ご存知のように、DNNというのは近年、大注目されている人工知能(AI)の基盤となる技術です。
さらに、先述の音源分離や残響除去などの技術を組み合わせることで、誤り率を7%程度にまで下げることに成功しました。これにより2位と大きく差をつけて、世界1位の音声認識精度を達成しました。
ちなみに、同じ音声を人間が聞いた場合、単語誤り率は12%程度なので、人間の性能を超えたことになります。
—人間の性能を上回ったというのはすごいですね!
中谷 その前年の2014年に開催されたREVERBチャレンジでは、ワンワン響くような残響のある環境での音声認識を競う大会でしたが、単語誤り率は約9%と、やはり世界第1位を獲得しました。DNN技術をいち早く取り入れ、さらに音を分解して、残響を取り除く技術を使うことで、大幅にその性能を上げることができました。
こうした技術が、現在、一般に普及しつつある音声認識技術のベースをかたちづくってきたと言えます。
荒木 ところが、冒頭で、中谷さんが例に出した複数人の会話のように、複数人の話者が、雑談のようにそれぞれ自由なタイミングで話した場合に、それぞれの音声を取り出したり、誰が話しているのかを推定したりするのはまだまだ難しいのです。それこそが、まさに現在の我々の研究対象となっています。
人同士であれば、アイコンタクトもできますし、ウェブカメラなどを経由したとしても、声色や話している内容で、いま誰が話しているのかがわかりますが、機械にはそれがわからない。そこで、いま手がけているのが、誰がいつからいつまで話をしたかを、たとえ声が重なるような場面があったとしても推定できる「発話区間推定」の研究です。これが実現できると、自動的に話者を区別しながら議事録を書き起こしたり、雑音や残響の除去の精度を上げたりすることに役立ちます。
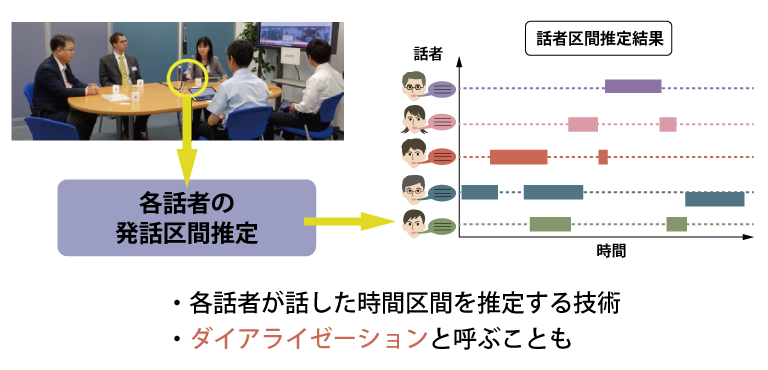
図2 会話シーンにおける話者区間推定
—自動で音声を認識して、それぞれの話し手ごとに文字として起こすということですか?
荒木 はい。現状は、フォーマルな会議など、それぞれがきちんと話をするような場面であれば、ある程度、正しく書き起こすことができます。ところが、カジュアルな日常会話になると途端に音声認識の精度が落ちてしまい、現状は25%くらいのエラーがあります。ボソボソ滑舌が悪かったり、とてもくだけた言葉でしゃべったりという、話し方のバリエーションに対応しきれていないことがエラーの主な原因です。また、エラー訂正や議事録の要約などのテキスト処理技術もあまり進んでいるとは言えません。
中谷 私たちは、リアルな日常会話を正確に音声認識をしてテキストに起こせるようになることをめざしているわけですが、そのためにはさらなるブレークスルーが必要になるというわけです。

図3 話者区間推定のリアルタイム処理の結果例
人間のように所望の声だけを聞くコンピュータをつくりたい
中谷 ここまでお話ししてきたように、コンピュータがやってきたことというのは、聞こえてくる音の中に含まれているすべての声や、残響、雑音を、各要素に切り分けたのちに、所望の音を取り出すという作業なんです。
いうなれば、聖徳太子の逸話のように、複数人の話を同時に聞いて、それぞれ切り分けて、認識しているようなものです。これはある意味すごいことですが、さきほど柏野さんがおっしゃったように、逆にそれがいまのコンピュータの限界でもあると言えます。つまり、これまでの方法では、一つの聞きたい声を聞き取るために、その他のすべての音を聞き取ることが必要でした。
一方、人間は「選択的聴取」といって、非常に騒がしい環境下にあっても、聞きたい人の声だけに注意を傾け、うまく聞き取ることができます。いわゆる「カクテルパーティ効果」と呼ばれる現象ですね。そういうコンピュータをつくれないか、というのが私たちの次なるチャレンジです。すなわち、人間と同じように、(仮に、すべての音は聞き取れなくても)聞きたい声だけは聞き取れる技術をつくりたいと考えています。
それを可能にする糸口となるのが、先述した深層ニューラルネットワーク(DNN)です。DNNは、2011年~2012年くらいにかけて、画像認識や化合物活性予測をはじめ、幅広い分野で既存技術の性能を次々に上回り、2015年にはGoogleのアルファ碁が人間のプロ囲碁棋士を破ったとして大いに注目されるようになりました。我々も、先の国際コンペティションでDNNを精度向上に役立てましたが、DNNはいまや、音処理技術の世界でももっとも注目されている技術なのです。
—DNN、深層学習など、AIの進展に欠かせない技術として、最近よく耳にするようになりましたが、そもそもどのようなしくみなのでしょうか。
中谷 簡単に説明すると、ニューラルネットワークというのは人間の脳のしくみから着想を得たネットワーク構造のことです。ニューロン(神経細胞)のふるまいを簡略化した素子を用いて、それらを多層(ディープ)に重ねて、入力から出力に向けて、少しずつ情報を変換しながら処理を行います。
たとえば、この仕組みを用いることで、二人の声が混ざった音声から所望の声だけを取り出すネットワークを構築できます。大量の学習データから、所望の声の特徴(着目すべき手掛かり)に基づき、徐々に目的の声だけを取り出せるように、ネットワークのつながりの強さ(重みパラメータ)を調整していくことで、そのようなネットワークをつくることができます。
ところが、すぐにわかるように、目的の声を取り出すのに、このやり方はあまり賢くありません。というのも、このDNNでは、学習した一人の人の声は取り出せても、別の人の声を取り出すことはできないからです。別の人の声を取り出そうとすると、また別の大量のデータでDNNを学習する必要があります。
—その声だけに特化したシステムになってしまうということですね。
中谷 ええ、そうなんです。そこで私たちは、「SpeakerBeam」という、一つのDNNでいろいろな人の声に注目して、その声を選択的に抽出することができる技術を開発しました。
まず、SpeakerBeam では、どの声に注目したいかを決めるために、その人の声の特徴を、所望の声を取り出す主ネットワークとは別の補助ネットワークで事前に抽出します(補助的特徴量の抽出)。この話者の特徴量の抽出に必要な音声は、わずか10秒程度で十分です。
次に、主ネットワークを二つの(実際にはもっと多くの)サブネットワーク(サブ隠れ層)に分けて、たとえば男性の声ならこの経路を、女性の声ならもう一つの経路を通るという具合に、使い分けられるようにしておきます。そのうえで、先ほど説明した補助ネットワークが抽出した話者の声の特徴に注目しなさいというメッセージを主ネットワークに与えてやると、補助的特徴量から計算される重み係数を用いて足し合わされ、その場でどの経路を通ればいいといったことが決定されます。その結果、その声の特徴に合致した声のみが抽出されるようになります。
次に、もし別の人の声を取り出したいときには、その人の声の特徴を補助ネットワークで抽出して用いることで、同じDNNから別の人の声を抽出できるようになります。
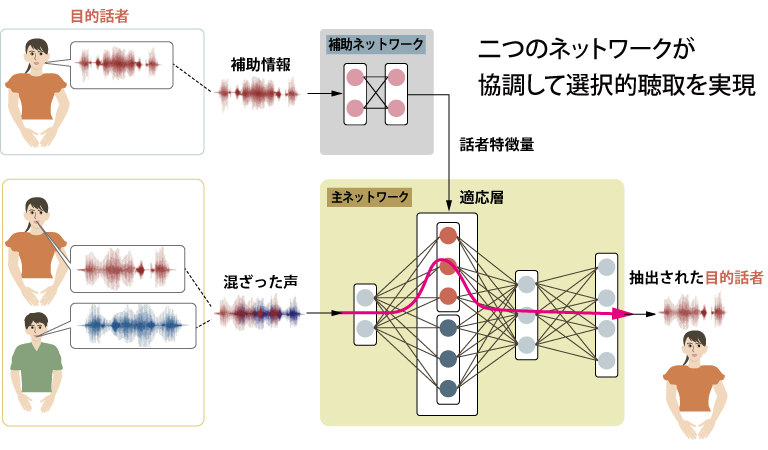
図4 SpeakerBeamの着眼点
このDNNを使って、二人の話者が同時に英字新聞ウォール・ストリート・ジャーナルを読み上げた混合音声から、目的の人の声だけを取り出す実験をしたところ、音声認識率を従来のDNNの音響モデルと比べて、大幅に改善することができました。まだ、完全にきれいな声を取り出すレベルには届きませんが、誤り率を大幅に下げることができたのは大きな前進です。
この技術の肝は何かと言えば、機械が人間と同じように声を聞き分けることができるようになる点にあります。人間には聞き取れないような音を聞いて分析するというのも、コンピュータに求められる役割の一つかもしれませんが、やはり人間とのコミュニケーションにおいては、人間と同じようなやり方で、自然なコミュニケーションができることが重要でしょう。その上で、コンピュータならではの高度な技術で人間を支援するというのが、私たちのめざす音声認識技術の姿なのです。
柏野 「コンピュータはまだまだ人間より劣っている」と言われてきた局面が、大きく変わろうとしているわけですね。中編では、人間とコンピュータの比較について、もう少し突っ込んで話ししたいと思います。
(取材・文=田井中麻都佳)
Next:» COLUMN [3] コンピュータが音を聞き分けるということ(中編)- 深層ニューラルネットワークと人間の比較から見えてくるもの - / Tomohiro NAKATANI, Shoko ARAKI & Makio KASHINO

» Website
» NTT コミュニケーション科学基礎研究所 / メディア情報研究部 / 信号処理研究グループ グループリーダ(上席特別研究員)
1991年、京都大学大学院工学研究科修士課程修了。博士(情報学)。残響除去技術 Weighted Prediction Error (WPE) 法など、多数の音響信号処理アルゴリズムを考案。日本オーディオ協会協会大賞 (2012年) 他受賞。

» Website
» NTT コミュニケーション科学基礎研究所 / メディア情報研究部 / 信号処理研究グループ 主任研究員
2000年、東京大学大学院工学系研究科修士課程修了。博士(情報科学)。 実環境における音源分離や音声強調について、多数のアルゴリズムを考案。 平成26年度 科学技術分野の文部科学大臣表彰 若手科学者賞 "音響信号のブラインド音源分離とその応用に関する先駆的研究"他受賞。

人間情報科学・認知神経科学
» Website
» スポーツ脳科学プロジェクト
1964年 岡山生まれ。1989年、東京大学大学院人文科学研究科修士課程修了。博士(心理学)。 NTTフェロー (NTT コミュニケーション科学基礎研究所 柏野多様脳特別研究室 室長)、東京工業大学工学院情報通信系特定教授、東京大学大学院教育学研究科客員教授。著書に『音のイリュージョン~知覚を生み出す脳の戦略~』(岩波書店、2010)、『空耳の科学―だまされる耳、聞き分ける脳』(ヤマハミュージックメディア、2012)他。
RELATED CONTENTS

COLUMN 2018.9.5
コンピュータが音を聞き分けるということ(中編)
- 深層ニューラルネットワークと人間の比較から見えてくるもの -
Tomohiro NAKATANI, Shoko ARAKI & Makio KASHINO
最近、深層ニューラルネットワーク(DNN)の登場で、音声認識の精度が一気に向上しつつある。しかしDNNの中身はブラックボックスになっていて、なぜ、そのような結果を導き出すのかがわからない。一方で、人間の音声認識のしくみ自体も、謎に包まれている部分がいまだ多くある。そうしたなか、近年、DNNで構築したモデルと人間とを比較する研究が注目されている。両者を比較することで、これまで謎に包まれていた人間の不思議が明らかになるかもしれない。
» READ MORE

COLUMN 2018.9.5
コンピュータが音を聞き分けるということ(後編)
- 機械との比較からわかる人間の特異性 -
Tomohiro NAKATANI, Shoko ARAKI & Makio KASHINO
NTTコミュニケーション科学基礎研究所の中谷智広さん、荒木章子さんらの研究グループでは、さまざまな音が混じり合った音声から、雑音などの不要な音を取り除きながらそれぞれの音を取り出す音源分離の技術や、音声認識の邪魔になる残響を取り除く技術の開発などを手がけている。最近では、深層ニューラルネットワーク技術を使った画期的な手法により、世界コンペティションで1位を獲得した。スマートフォンやスマートスピーカーの音声認識の向上に資する研究について話を聞いた。
» READ MORE

MUSIC 2018.8.16
Auditory Illusion in Music
- [2] カクテルパーティとモテトゥス、そして「音楽的な耳」 -
Risa MORIYA
「音楽的な耳」を持つ、ということはどのようなことでしょうか。音楽家にとって必要不可欠な聴取の能力について、脳科学で言われるところの「カクテルパーティ効果」という切り口から考察してみます。
» READ MORE

MUSIC 2018.8.16
Musical illusion
- Compliment -
Leonid ZVOLINSKII
この曲例は、沢山の音の中から必要な音として選択された任意の音に集中することができるという、私たちの聴覚の能力を実証するものです。曲のタイトル ≪Compliment≫ は、≪complementary≫という言葉から、言葉遊びで付けたものですが、作品の気分を反映しているだけではなく、作曲にあたって用いたテクニックを暗に示しています。コンプリメンタリー、つまり相補的な原則が曲全体に浸透し、複数のリズムがモザイク状に融合されて全体的なリズムを形作っています。同様に、それぞれ異なるロジックで作ったハーモニーを持つ楽器たちが織り合わさって、全体のハーモニーが生成されています。
» READ MORE

MUSIC 2018.8.16
Musical illusion
- The Dream of Flowers -
Leonid ZVOLINSKII
今回はコンテクストを持つ芸術としての音楽についてお話したいと思います。 音楽は時間の中で動くもので、絶えずそれぞれの具体的な瞬間や場面までと、その後に鳴り響くものというコンテクスト(脈絡、文脈)の中に存在するものです。それは音楽の水平とよばれる時間軸で、そこでは出来事自体のみならず、その秩序も作品全体の印象を形作ります。まさにこの効果のおかげで、時には長調の音楽も大きな悲しみとして感じられることもあります。例えば、チャイコフスキーの交響曲6番の1楽章の最後を思い出してみましょう。それ以前に出てきた全てのドラマチックな衝突を背景として、全体としては、勝利というよりも、この音楽の「主人公」との明るくも悲しい別れとして感じられます。この部分だけを聴くならば、何倍も喜びに満ちて感じられるはずです。
» READ MORE
SERIES
- » COLUMN [1] 「聞くこと」について自由に語れるような、ひらかれた場をつくりたい / Makio KASHINO
- » COLUMN [2] 音楽とスポーツの密なる関係(前編)- 楽器演奏の上達とスポーツの上達は似ている - / Shinichi FURUYA & Makio KASHINO
- » COLUMN [2] 音楽とスポーツの密なる関係(中編)- 左右の奇妙な非対称と局所性ジストニア - / Shinichi FURUYA & Makio KASHINO
- » COLUMN [2] 音楽とスポーツの密なる関係(後編)- 全身を最適にコントロールするために必要なこと - / Shinichi FURUYA & Makio KASHINO
- » COLUMN [3] コンピュータが音を聞き分けるということ(前編)- 騒がしい環境下で世界一の音声認識精度を達成 - / Tomohiro NAKATANI, Shoko ARAKI & Makio KASHINO
- » COLUMN [3] コンピュータが音を聞き分けるということ(中編)- 深層ニューラルネットワークと人間の比較から見えてくるもの - / Tomohiro NAKATANI, Shoko ARAKI & Makio KASHINO
- » COLUMN [3] コンピュータが音を聞き分けるということ(後編)- 機械との比較からわかる人間の特異性 - / Tomohiro NAKATANI, Shoko ARAKI & Makio KASHINO
- » COLUMN [4] 身体技能のあくなき上達をめざして(前編) - 大人でもスポーツや楽器はうまくなる? - / Kazuo OKANOYA & Makio KASHINO
- » COLUMN [4] 身体技能のあくなき上達をめざして(後編) - 学びに必要な条件とは - / Kazuo OKANOYA & Makio KASHINO
- » COLUMN [5] 遠隔時代の身体(前編) - 視覚障がい者との接触コミュニケーションを通じて遠隔コミュニケーションの可能性を探る - / Asa ITO
- » COLUMN [5] 遠隔時代の身体(後編) - 固有な身体性と遠隔コミュニケーションについて考える - / Asa ITO & Makio KASHINO
- » COLUMN [6] ドラムと研究の両輪で、音楽と人間の本質に迫る(前編) - 奏者からドラマー研究の開拓者へ - / Shinya FUJII & Makio KASHINO
- » COLUMN [6] ドラムと研究の両輪で、音楽と人間の本質に迫る(後編) - 多様性のサイエンスから人間とは何かを解き明かしたい - / Shinya FUJII & Makio KASHINO